

This page explains the Swaledale census district boundaries, and how I transcribed the census data for later use in my numbercrunching essays. I have transferred the census data to Excel files, and added some useful extra information. There are 56 files, divided into eight districts, as mapped below.
Please email me if you would like any of these data files for your own research. These files are really flat databases and you can sort, count, merge, as much as you need. For example, you could create one big list of all censuses for 1871 then sort them to display all the ALDERSON families sorted by address � very handy for finding cousins with the same names and ages. Or you could make one big list for everyone in Muker from 1841 to 1901 and track the generations. All the lists are designed to be sorted back into their original files.
Census district boundaries
Here is a map showing the boundaries of each of my eight census districts. I haved used "Melbecks" because the census does, even though the township does not exist as a town or village! The boundaries are very approximate indeed, because I used only the 1851 census placenames to position outlying places in one or other district, but it gives you some idea. I have not checked the map against parish boundary maps.
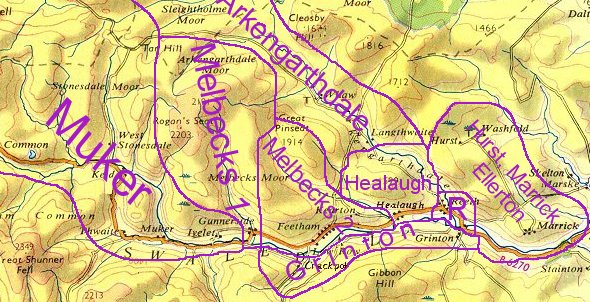
- Muker is the largest. The district certainly includes Tan Hill, Stonesdale and Birkdale Common but I do not know its north-westerly boundary.
- Melbecks 1 covers Gunnerside and Lodge Green, up Gunnerside Gill to Winterings then east to Moor House up on the top of the moor.
- Melbecks 2 uses the river as its southern boundary and includes Low Row, Blades and Feetham but the line between it and Arkengarthdale is a guess.
- Arkengarthdale starts just before Langthwaite and follows the turnpike up to Shepherds Lodge.
- Healaugh is easier to map since many of the places named in 1851 are on modern maps.(But Town End Hall Farm, the site for one of my essays, was switched regularly between Reeth and Healaugh in consecutive censuses; you have to persevere.)
- Reeth (R on the map) includes Fremington, although they were originally recorded separately, because of their close proximity and Fremington�s small numbers.
- Grinton, having swooped downstream to capture Cogden Hall, turns and stretches back all along the south bank of the river almost as far as Gunnerside.
- Marrick, Hurst and Ellerton Abbey were again originally recorded separately but I grouped them together because their individual populations were so small.
I did make an Excel list for myself of all the place names used in each census from 1841 to 1871. Some names appear only once. The list includes a map reference for the 2002 edition of the Philip�s North Yorkshire Street Atlas, where I have found one. If you would like a copy please email me.
What do the data files look like?
In order to give you the widest choice for what you might want, there are 56 separate Excel files - one for each census for the eight census districts.
Here is what the data lists look like, illustrated by two Healaugh households in 1861. The formatting and content is explained below:
Healaugh 1861
RG 9 3673 folio 26-> (see explanatory notes)
| Year | # | Place | Address | Ho | Surname | First Names(s) | Rel | Status | Age | YoB | Occupation | Born | Unique ID |
| 1861 | 22 | Healaugh | village | 1 | KENDALL | Thomas (absent) | Head | M | 23 | 1838 | farmer & carrier [in 1871] | Yks Riddings | 518610097 |
| 1861 | 22 | Healaugh | village | KENDALL | Ann | wife | M | 23 | 1838 | farmer's wife | Yks Reeth | 518610098 | |
| 1861 | 22 | Healaugh | village | KENDALL | Mark | son | 2 | 1859 | infant | Yks Healaugh | 518610099 | ||
| 1861 | 22 | Healaugh | village | KENDALL | Robert | son | 0.25 | 1861 | infant | Yks Healaugh | 518610100 | ||
| 1861 | 50.5 | Healaugh | Thiernswood | 1 | unoccupied | 518619999 | |||||||
| 1861 | 67 | Healaugh | Castle | 1 | ALDERSON | John | Head | M | 43 | 1818 | farmer >50 acres | Yks Gunnerside | 518610331 |
| 1861 | 67 | Healaugh | Castle | ALDERSON | Elizabeth? (absent) | wife | M | 43? | 1818? | farmer's wife [visiting #2008 Muker?] | 518610332 | ||
| 1861 | 67 | Healaugh | Castle | ALDERSON | George | son | U | 16 | 1845 | lead miner | Yks Gunnerside | 518610333 | |
| 1861 | 67 | Healaugh | Castle | ALDERSON | Doratha | dau | 11 | 1850 | scholar | Yks Gunnerside | 518610334 | ||
| 1861 | 67 | Healaugh | Castle | ALDERSON | John | son | 7 | 1854 | scholar | Yks Gunnerside | 518610335 | ||
1861 Healaugh total households: 79
1861 Healaugh total population: 404
1861 Healaugh total unoccupied: 4
Differences
The following notes explain how the lists differ from the originals, and why.
- Each list shows the original Public Record Office volume and folio references used. Some censuses were spread over more than one set of pages.
- black font = an accurate copy from the census (except for any typing errors not yet noticed)
- red font = unoccupied houses
- blue font = I have added the text
- blue italic font = I have added an occupation description to match my standard list
- orange font = I have added a note or comment
Column headings are used as follows:
Year: Each row shows the year in which the data was collected, in case you later merge years and need to know, or to re-sort.
# shows accurately the original schedule number given to each each family, even though it might be illogical, so you can quickly find the entry again in the original census, UNLESS the enumerator started again at 1 when moving to the next hamlet, in which case I have renumbered the household as 101, to maintain the census order when re-sorting (and 201, 301 if needed).
- The 1841 census lists, which did not have any numbers, are numbered by me in the same way for consistency and cross-reference.
- Some enumerators gave new #s to lodgers or servants in the same house. Others did not. I have kept each number.
- Uninhabited houses did not have a schedule #. I have identified them by giving them the number of the previous household, plus a decimal .5, so they can be re-sorted into their correct position along the census route. Sometimes the enumerator gave a number to an unoccupied house, so it has to stay.
- Sometimes the enumerator correctly gave a number to an unoccupied house where the owner was away on the night but it is impossible to tell now whether this rule was always followed. Absent householders, who will always be a mystery unless you have other documentary proof of occupation such as trade directory entries, have been given one unique ID, just in case a name turns up later.
Place is usually the name of the nearest big village or town - usually but not always whatever was written on the top of the census sheet to identify the place. I have repeated it on each row to make it easier to locate each person�s home if the data is re-sorted.
Address is usually the information written in the Road/Street column on the census form. But if the village name is already in the Place column, I have changed the text to "village" or "hamlet" to show that the household was (apparently) in the village and not up on the hillsides. I may well be wrong. Some enumerators were more painstaking than others so the level of detail varies between censuses. The 1891/1901 censuses also counted how many rooms were occupied by the household, if less than 5. Presumably this means kitchen+living rooms+bedrooms but I don�t know. I have shown the given number against the address - eg (3r) = 3 rooms.
Ho indicates the mark used by the enumerator to indicate the next household. Because of unreliability I have ignored any markings for multiple occupancy of a house and have treated every family as a separate household. You will need to go back to the original census documents, or to Christine Amsden's transcripts, to check which families might have lived together in a house.
Surname is self-explanatory and is transcribed as written, even though you may know that it is wrong! Often two people of close age in the same district have the same name. In Gunnerside, I started to find and mark them when the age gap was less than about 5 yrs, but there are simply too many so I stopped. And handwritten capital Ss and Ls can be alarmingly similar, so if you are a Liddle or a Siddle look for both names, since there is no clue now for the transcriber unfamiliar with the families.
First name(s) is also self-explanatory, though I found a Rogerina where a supervisor had added "ina" to a son�s name to correct the enumerator�s mistake of putting his age in the female column. I have put this right. Also, remember that some families used abbreviations in daily life, so Margaret could be known as Peggy, or Ann as Nanny. I have not changed the original entry, though I have sometimes added the alternative name when it occurs in another census. Second names are sometimes given in full, sometimes as an initial letter, sometimes not at all. In the case of the REYNOLDSONs of Thorn the second initial is crucial, because John and Mary Ann named their boys: John William, John R, John, John Guy.
Relationship, Status, Age is as recorded, but
- The 1841 census did not record relationships or marital status, so I assumed that a man and woman with small children were married to each other and were the parents of those children. Later censuses may prove me wrong but I did not check every one. Some households are so intriguing that I could not resist suggesting relationships, but these are speculation and marked with ?s.
- I have changed the archaic use of "son-in-law" to "step-son" where it is clearly appropriate.
- Some given relationships may be misleading. You may find sisters, nieces, even daughters described as servants. Sometimes the adjacent censuses help here.
- A surprising number of 14- and 15-year-olds were originally marked as Unmarried - when did the marriage age limit of 16 come in?
- Remember that in 1841 ages might be rounded down to the nearest 5 years.
YoB is calculated by deducting the given age from the census year. I had to decimalise babies under the age of 1. This data field becomes very useful when looking for the same person in a different census, but be prepared for variations of two or three years; occasionally even more. The enumerator could only record what he was told, and sometimes people did not know themselves.
Occupation: this column has the most differences from the original data, as explained in Original Data though I have tried to put all the additions and assumptions in blue italics.
Born: is as recorded in the census, it may not always be accurate or consistent. Where the information was missing I looked for the person in the other censuses OR (esp in 1841) looked for a similar family with the same surname and used that data.
Unique ID: I have given every person a unique ID within each census data set. I know that this means the same person will then have a different Unique ID in the next census, but this is one of the limitations of flat databases!
For example: in Unique ID 218610056
- 2 is the district
- 1861 is the year
- 0056 is the 56th person on the census list
The districts are based on the census districts, counting from the top of the dale, and are: 1 = Muker, 2 = Melbecks 1 (Gunnerside), 3 = Melbecks 2 (Low Row), 4 = Arkengarthdale, 5 = Healaugh, 6 = Reeth and Fremington, 7 = Grinton, 8 = Marrick, Hurst and Ellerton Abbey. I have not (yet) included Marske but if I ever do it will be numbered 9.
You can use this unique ID to sort everyone back into their original census order after doing a merged search. To sort back to the original census order within any one district and year, sort by # then Unique ID.
- Empty houses are all numbered xxxxx9999. To exclude them from the main list, sort by Unique ID.
Downloads and copyright
You may well decide that you want to work on the data yourself. Send me an email with the dates and places you are interested in, and I will email the files back to you. Please keep the National Archives copyright in mind (and mine) if you later publish your own work.
- The lists are offered as individual years in individual districts, to keep them short and therefore quick to send. There are 56 altogether (seven censuses for each of the eight districts detailed above).
- If you do not use Excel I can send the files as slash-delimited text files and you can import them into your own spreadsheet or word processor. To keep the font colour and formatting safe, though, the files will have to be sent in .rtf format, which means they will be quite big.
How big are the files?
In Excel format, the smallest file is 49Kb and the largest is 300Kb. Most are 100-200Kb. We discovered by experiment (well, John did) that using the built-in 'Save as HTML' option in Excel made the files considerably larger, which is why we have not done so. All 58 files occupy just over 8Mb. My working folder, which also includes eight big consolidated files for each census year, plus odd files for counting families with young children, and smallholders, and people who moved away, and statistics and graphs, occupies nearly 20Mb.
How to count in Excel
If you have a column of occupations can use Excel's COUNTIF formula to scan the Occupation column (Col L in the example below) and display how many matching occupations exist in the worksheet. This is why it is crucial to use standard descriptions for occupations - searching for lead miner (two words) would not find leadminer.
You can use this process to build up a total from any number of worksheets within any number of spreadsheets. The (slightly illogical) example below is counting the number of lead miners in two data files: 4Reeth1861.xls and 5Healaugh1861.xls. Build the formula by highlighting the target column in each worksheet as you go, and Excel will identify the spreadsheet, worksheet and column address. (The second mention of "1861" in each half of the formula is because I had renamed the worksheet tab from Excel's default Sheet 1 to 1861; this had me perplexed for a while). The formula would look something like this:
=COUNTIF('[4Reeth1861.xls]1861'!$L:$L,"lead miner") +COUNTIF('[5Healaugh1861.xls]1861'!$L:$L,"lead miner *")
You will see that the formula has used * as a wildcard to extend the count. It took me some time to work out the subtleties! Here are some examples:
farmer Excel will only count if farmer is the only word in the cell.
farmer* Excel will count every cell where the word farmer is followed by other words, such as farmer of 20 acres, or farmer & bootmaker or farmer's wife. To exclude farmer's wife all you have to do is make the formula's text string say farmer * - note the crucial space before the asterisk.
*farmer* Excel will count any cell containing the word farmer anywhere in the cell, for example, lead miner & farmer of 20 acres.
*bootmaker will find each farmer & bootmaker, but not any farmer & bootmaker & innkeeper.
If you want to count everyone involved in farming, use farm* to pick up farmers, farm labourers, farmer�s wives, and so on, or grocer�s* to count all wives, assistants, daughters and so on. The best way to be accurate is to work on a small data set first, and cross-check the calculation by counting the results yourself to find any unexpected or unwanted hits or misses.
When it comes to counting notional jobs, such as lead miner�s son, you may decide to count them separately, or as � a miner, or whatever you think sensible. You might also be able to use SUMIF to match text in a specified cell, rather than having to type "bootmaker" each time, but I can't see how SUMIF deals with wildcards. Whatever method you use it would be a kindness to your readers, if you plan to publish the information, to explain just how you did your counting.